I have two items about brainlike computing. The first item hearkens back to memristors, a topic I have been following since 2008. (If you’re curious about the various twists and turns just enter the term ‘memristor’ in this blog’s search engine.) The latest on memristors is from a team than includes IBM (US), École Politechnique Fédérale de Lausanne (EPFL; Swizterland), and the New Jersey Institute of Technology (NJIT; US). The second bit comes from a Jülich Research Centre team in Germany and concerns an approach to brain-like computing that does not include memristors.
Multi-memristive synapses
In the inexorable march to make computers function more like human brains (neuromorphic engineering/computing), an international team has announced its latest results in a July 10, 2018 news item on Nanowerk,
Two New Jersey Institute of Technology (NJIT) researchers, working with collaborators from the IBM Research Zurich Laboratory and the École Polytechnique Fédérale de Lausanne, have demonstrated a novel synaptic architecture that could lead to a new class of information processing systems inspired by the brain.
The findings are an important step toward building more energy-efficient computing systems that also are capable of learning and adaptation in the real world. …
A July 10, 2018 NJIT news release (also on EurekAlert) by Tracey Regan, which originated by the news item, adds more details,
The researchers, Bipin Rajendran, an associate professor of electrical and computer engineering, and S. R. Nandakumar, a graduate student in electrical engineering, have been developing brain-inspired computing systems that could be used for a wide range of big data applications.
Over the past few years, deep learning algorithms have proven to be highly successful in solving complex cognitive tasks such as controlling self-driving cars and language understanding. At the heart of these algorithms are artificial neural networks – mathematical models of the neurons and synapses of the brain – that are fed huge amounts of data so that the synaptic strengths are autonomously adjusted to learn the intrinsic features and hidden correlations in these data streams.
However, the implementation of these brain-inspired algorithms on conventional computers is highly inefficient, consuming huge amounts of power and time. This has prompted engineers to search for new materials and devices to build special-purpose computers that can incorporate the algorithms. Nanoscale memristive devices, electrical components whose conductivity depends approximately on prior signaling activity, can be used to represent the synaptic strength between the neurons in artificial neural networks.
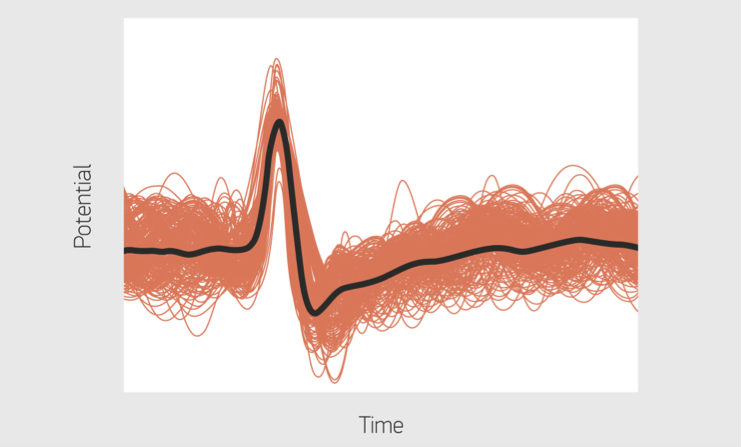
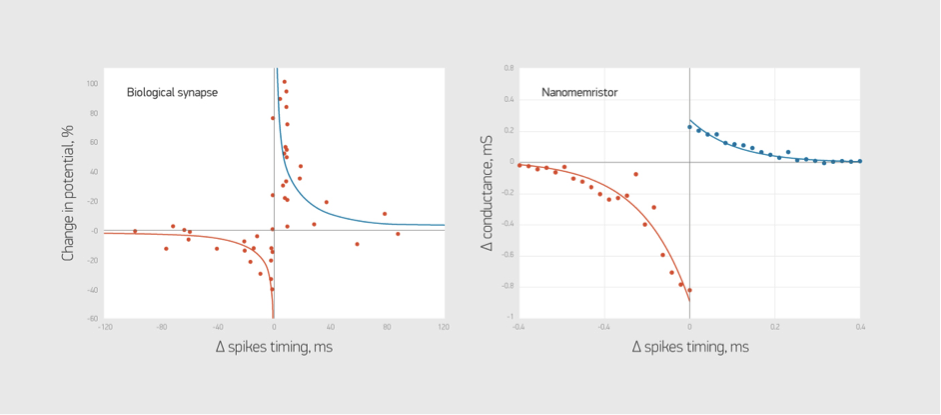
While memristive devices could potentially lead to faster and more power-efficient computing systems, they are also plagued by several reliability issues that are common to nanoscale devices. Their efficiency stems from their ability to be programmed in an analog manner to store multiple bits of information; however, their electrical conductivities vary in a non-deterministic and non-linear fashion.
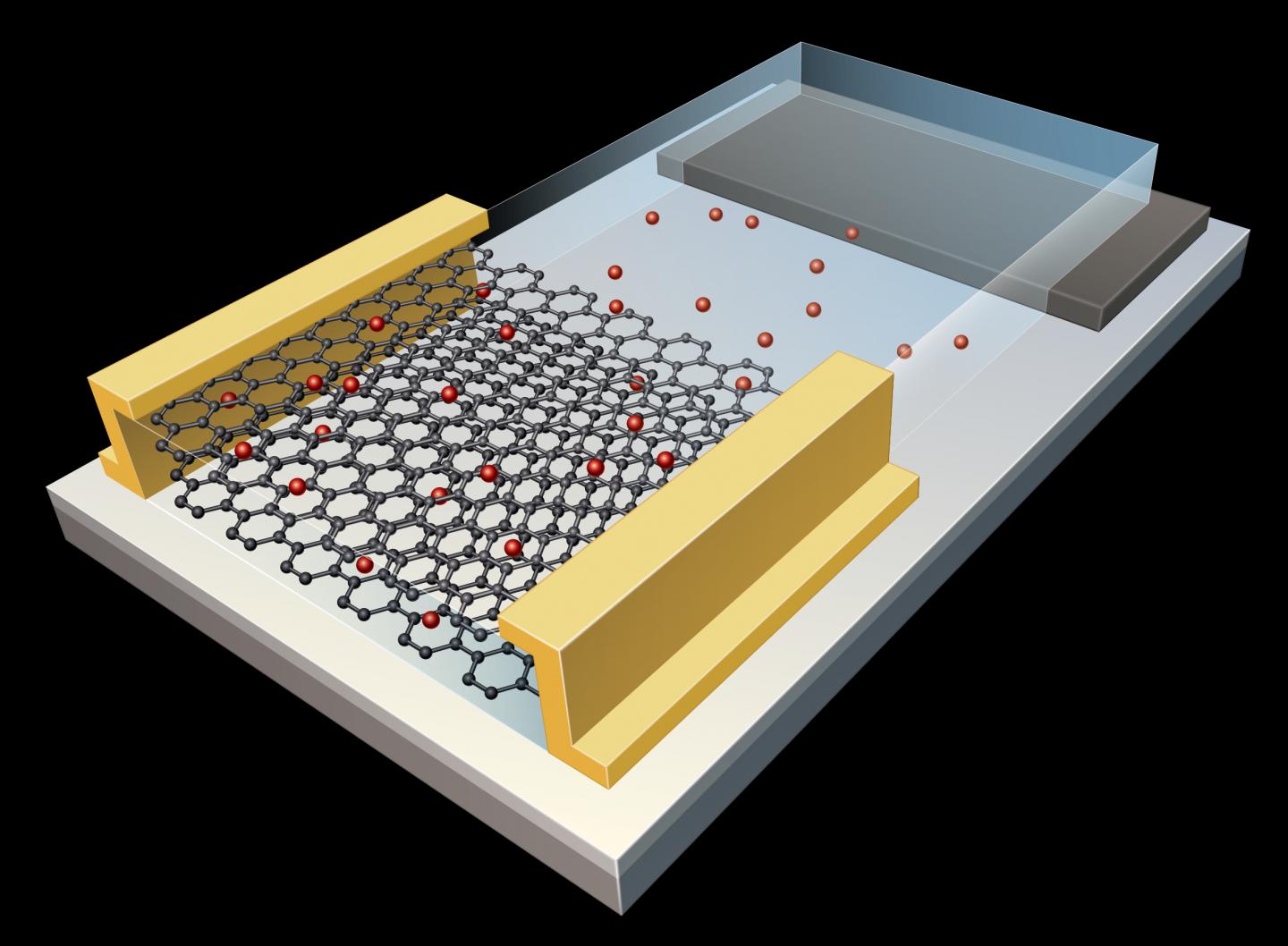
In the experiment, the team showed how multiple nanoscale memristive devices exhibiting these characteristics could nonetheless be configured to efficiently implement artificial intelligence algorithms such as deep learning. Prototype chips from IBM containing more than one million nanoscale phase-change memristive devices were used to implement a neural network for the detection of hidden patterns and correlations in time-varying signals.
“In this work, we proposed and experimentally demonstrated a scheme to obtain high learning efficiencies with nanoscale memristive devices for implementing learning algorithms,” Nandakumar says. “The central idea in our demonstration was to use several memristive devices in parallel to represent the strength of a synapse of a neural network, but only chose one of them to be updated at each step based on the neuronal activity.”
Here’s a link to and a citation for the paper,
Neuromorphic computing with multi-memristive synapses by Irem Boybat, Manuel Le Gallo, S. R. Nandakumar, Timoleon Moraitis, Thomas Parnell, Tomas Tuma, Bipin Rajendran, Yusuf Leblebici, Abu Sebastian, & Evangelos Eleftheriou. Nature Communications volume 9, Article number: 2514 (2018) DOI: https://doi.org/10.1038/s41467-018-04933-y Published 28 June 2018
This is an open access paper.
Also they’ve got a couple of very nice introductory paragraphs which I’m including here, (from the June 28, 2018 paper in Nature Communications; Note: Links have been removed),
The human brain with less than 20 W of power consumption offers a processing capability that exceeds the petaflops mark, and thus outperforms state-of-the-art supercomputers by several orders of magnitude in terms of energy efficiency and volume. Building ultra-low-power cognitive computing systems inspired by the operating principles of the brain is a promising avenue towards achieving such efficiency. Recently, deep learning has revolutionized the field of machine learning by providing human-like performance in areas, such as computer vision, speech recognition, and complex strategic games1. However, current hardware implementations of deep neural networks are still far from competing with biological neural systems in terms of real-time information-processing capabilities with comparable energy consumption.
One of the reasons for this inefficiency is that most neural networks are implemented on computing systems based on the conventional von Neumann architecture with separate memory and processing units. There are a few attempts to build custom neuromorphic hardware that is optimized to implement neural algorithms2,3,4,5. However, as these custom systems are typically based on conventional silicon complementary metal oxide semiconductor (CMOS) circuitry, the area efficiency of such hardware implementations will remain relatively low, especially if in situ learning and non-volatile synaptic behavior have to be incorporated. Recently, a new class of nanoscale devices has shown promise for realizing the synaptic dynamics in a compact and power-efficient manner. These memristive devices store information in their resistance/conductance states and exhibit conductivity modulation based on the programming history6,7,8,9. The central idea in building cognitive hardware based on memristive devices is to store the synaptic weights as their conductance states and to perform the associated computational tasks in place.
The two essential synaptic attributes that need to be emulated by memristive devices are the synaptic efficacy and plasticity. …
It gets more complicated from there.
Now onto the next bit.
SpiNNaker
At a guess, those capitalized N’s are meant to indicate ‘neural networks’. As best I can determine, SpiNNaker is not based on the memristor. Moving on, a July 11, 2018 news item on phys.org announces work from a team examining how neuromorphic hardware and neuromorphic software work together,
A computer built to mimic the brain’s neural networks produces similar results to that of the best brain-simulation supercomputer software currently used for neural-signaling research, finds a new study published in the open-access journal Frontiers in Neuroscience. Tested for accuracy, speed and energy efficiency, this custom-built computer named SpiNNaker, has the potential to overcome the speed and power consumption problems of conventional supercomputers. The aim is to advance our knowledge of neural processing in the brain, to include learning and disorders such as epilepsy and Alzheimer’s disease.
A July 11, 2018 Frontiers Publishing news release on EurekAlert, which originated the news item, expands on the latest work,
“SpiNNaker can support detailed biological models of the cortex–the outer layer of the brain that receives and processes information from the senses–delivering results very similar to those from an equivalent supercomputer software simulation,” says Dr. Sacha van Albada, lead author of this study and leader of the Theoretical Neuroanatomy group at the Jülich Research Centre, Germany. “The ability to run large-scale detailed neural networks quickly and at low power consumption will advance robotics research and facilitate studies on learning and brain disorders.”
The human brain is extremely complex, comprising 100 billion interconnected brain cells. We understand how individual neurons and their components behave and communicate with each other and on the larger scale, which areas of the brain are used for sensory perception, action and cognition. However, we know less about the translation of neural activity into behavior, such as turning thought into muscle movement.
Supercomputer software has helped by simulating the exchange of signals between neurons, but even the best software run on the fastest supercomputers to date can only simulate 1% of the human brain.
“It is presently unclear which computer architecture is best suited to study whole-brain networks efficiently. The European Human Brain Project and Jülich Research Centre have performed extensive research to identify the best strategy for this highly complex problem. Today’s supercomputers require several minutes to simulate one second of real time, so studies on processes like learning, which take hours and days in real time are currently out of reach.” explains Professor Markus Diesmann, co-author, head of the Computational and Systems Neuroscience department at the Jülich Research Centre.
He continues, “There is a huge gap between the energy consumption of the brain and today’s supercomputers. Neuromorphic (brain-inspired) computing allows us to investigate how close we can get to the energy efficiency of the brain using electronics.”
Developed over the past 15 years and based on the structure and function of the human brain, SpiNNaker — part of the Neuromorphic Computing Platform of the Human Brain Project — is a custom-built computer composed of half a million of simple computing elements controlled by its own software. The researchers compared the accuracy, speed and energy efficiency of SpiNNaker with that of NEST–a specialist supercomputer software currently in use for brain neuron-signaling research.
“The simulations run on NEST and SpiNNaker showed very similar results,” reports Steve Furber, co-author and Professor of Computer Engineering at the University of Manchester, UK. “This is the first time such a detailed simulation of the cortex has been run on SpiNNaker, or on any neuromorphic platform. SpiNNaker comprises 600 circuit boards incorporating over 500,000 small processors in total. The simulation described in this study used just six boards–1% of the total capability of the machine. The findings from our research will improve the software to reduce this to a single board.”
Van Albada shares her future aspirations for SpiNNaker, “We hope for increasingly large real-time simulations with these neuromorphic computing systems. In the Human Brain Project, we already work with neuroroboticists who hope to use them for robotic control.”
Before getting to the link and citation for the paper, here’s a description of SpiNNaker’s hardware from the ‘Spiking neural netowrk’ Wikipedia entry, Note: Links have been removed,
Neurogrid, built at Stanford University, is a board that can simulate spiking neural networks directly in hardware. SpiNNaker (Spiking Neural Network Architecture) [emphasis mine], designed at the University of Manchester, uses ARM processors as the building blocks of a massively parallel computing platform based on a six-layer thalamocortical model.[5]
Now for the link and citation,
Performance Comparison of the Digital Neuromorphic Hardware SpiNNaker and the Neural Network Simulation Software NEST for a Full-Scale Cortical Microcircuit Model by
Sacha J. van Albada, Andrew G. Rowley, Johanna Senk, Michael Hopkins, Maximilian Schmidt, Alan B. Stokes, David R. Lester, Markus Diesmann, and Steve B. Furber. Neurosci. 12:291. doi: 10.3389/fnins.2018.00291 Published: 23 May 2018
As noted earlier, this is an open access paper.